| University | Singapore University of Social Science (SUSS) |
| Subject | ANL303: Fundamentals of Data Mining |
Question 1
In Singapore, despite the renowned efficiency of its healthcare system, the growing prevalence of chronic diseases poses a significant challenge. With healthcare costs on the rise, the financial burden on patients and families is becoming increasingly concerning. Amidst these challenges, it’s evident that many individuals grappling with chronic diseases also experience varying levels of depression. However, while medical attention primarily focuses on treating the physical manifestations of these conditions, the mental well-being of patients is often overlooked.
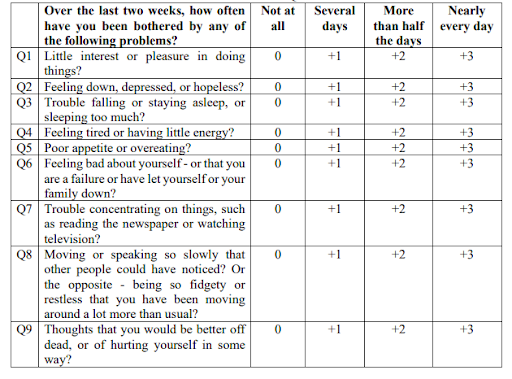
To address this critical gap, a data mining project is conducted to investigate depression among patients with chronic diseases. The Patient Health Questionnaire-9 (PHQ-9) is a widely used tool for detecting depression. It comprises nine questions, as shown in Table 1. Each response to these questions is assigned a score (0, +1, +2, +3) to gauge the severity of symptoms. The first two questions (Q1 and Q2) are used for initial screening, with their scores summed up to assess the likelihood of major depressive disorder. Should major depression disorder be indicated, all nine questions (from Q1 to Q9) are referred to further evaluate the severity of depression.
Table 1. The PHQ-9
Hire a Professional Essay & Assignment Writer for completing your Academic Assessments
Native Singapore Writers Team
- 100% Plagiarism-Free Essay
- Highest Satisfaction Rate
- Free Revision
- On-Time Delivery
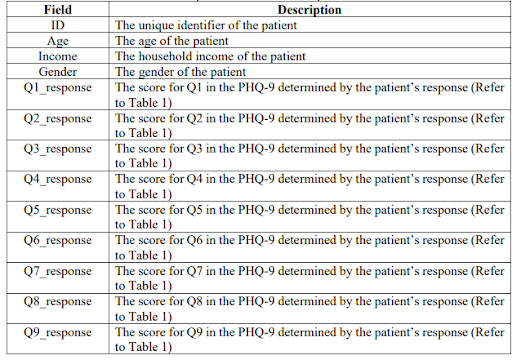
A dataset (“depression.csv”) has been collected, comprising records of patients diagnosed with chronic diseases along with their responses to the PHQ-9. Demographic information is also incorporated within the dataset to provide an understanding of the patient cohort under study. Table 2 describes the fields contained in the dataset.
Table 2. Description of the dataset “depression.csv”
In this question, you are going to import the dataset to IBM SPSS Modeler and perform all data mining tasks (including data preparation, if any) using IBM SPSS Modeler.
(a) Propose two (2) additional fields that can be included in the dataset and discuss how their inclusion in the analysis can advance our understanding of depression among patients with chronic diseases. Present your answer in the following format:

(b) Identify the data quality issue(s) in the dataset and perform data cleaning. Then, in less than 100 words, briefly describe how you prepare the dataset to make it suitable for data mining using IBM SPSS Modeler. Provide the necessary screenshot(s).
Buy Custom Answer of This Assessment & Raise Your Grades
(c) Domain experts have identified a score of 3 as the optimal cut-off point when using Q1 and Q2 in the PHQ-9 to screen for depression. If the score is 3 or above, major depression disorder is likely. Create a new field to indicate for each patient whether major depression disorder is detected (positive or negative).
Briefly discuss how the new field is created using IBM SPSS Modeler and report the number of positive cases. Provide the necessary screenshot(s).
(d) Among the positive cases, calculate the total score from Q1 to Q9 to determine the severity of depression according to the following categories:
-0-4: None
– 5-9: Mild
– 10-14: Moderate
– 15-19: Moderately severe
– 20-27: Severe
Provide one (1) graphical display that can identify the top two categories with the highest number of positive cases.
Briefly discuss how the graph is generated using IBM SPSS Modeler and provide the necessary screenshot(s).
(e) It is observed that patients with major depression disorder are experiencing various levels of depression severity. Construct a K-Means model that can help identify the profile of patients with major depression disorder (i.e., positive cases) who are more likely to fall into the moderately severe or severe categories.
Your answer should include the following:
– Describe how you identify your model as the final best model.
– For the chosen model, provide screenshots of the models’ outputs (showing the model summary, cluster sizes, and cluster comparison) and describe the profile of each cluster.
– Discuss how you identify the target group(s) based on the chosen model
(f) With the dataset described in Table 1, assess the suitability of association analysis for identifying the profile of new patients (i.e., patients who have not participated in the PHQ-9) who are likely to fall into the severe depression category.
If it is suitable, discuss (i) which field(s) listed in Table 1 should be included as the antecedent and consequent, and
(ii) if any data preparation task should be done. If it is not suitable, provide your justification. You are not required to use IBM SPSS Modeler for part (f)
Another 10 marks are allocated for your writing. (Up to 25 marks of penalties will be imposed for inappropriate or poor paraphrasing. For serious cases, they will be investigated by the examination department. More information on effective paraphrasing strategies can be found at https://academicguides.waldenu.edu/writingcenter/evidence/paraphrase/effective)
Stuck with a lot of homework assignments and feeling stressed ? Take professional academic assistance & Get 100% Plagiarism free papers
Are you facing challenges with your ANL303 Fundamentals of Data Mining, Group-based Assignment? Our Singapore assignment writing help is the solution! We ensure TMA solutions on time and provide reliable urgent assignment help services for your convenience. Experience affordable, high-quality services backed by 100% human-written assignments—no AI—for guaranteed A+ results. Plus, we deliver on-time and ensure plagiarism-free content. Let us help you excel in your studies!

Looking for Plagiarism free Answers for your college/ university Assignments.
- GSBS6514 Leadership in Contemporary Organisations Assessment Brief 2026 | UON
- ICT340 Application Analysis and Design End-of-Course Assessment 2026
- MGT304 Business Consultancy Project Assessment Brief 2026 | MDIS
- FMT306 Strategic Asset, Property and Facilities Management End-of-Course Assessment January Semester 2026
- PSY373 Psychology of Nonverbal Behaviours End-of-Course Assessment January Semester 2026 | SUSS
- MGE302 Applied Economics Individual Assignment 2026 | SIM
- POL351 Comparative Politics in Southeast Asia End-of-Course Assessment 2026 | SUSS
- SOC313 Sociology of Education End-of-Course Assessment 2026 | SUSS
- BPM213 Procurement Management Tutor-Marked Assignment 2, 2026 | SUSS
- MNGT3013 Innovation Management Assessment 1, 2026 | University of Newcastle